In a previous post I walked through some topics and listed reasons why NoSQL and SQL are better to use in different situations, but now I wanted to give an opportunity to give a more basic introduction on what NoSQL is all about.
Different ways to store data in NoSQL:
key:value (example redis)
document -json (example mongo-DB)
Difference? These are pretty similar actually. In key/value, you can store metadata for particular details for indexing, while in document, you typically have a "id" field as part of your json. The differences are in reality, blurry.
Schema-(less?):
Though NoSQL has the flexibility of no schema, its often misleading. For instance, assuming you have a database of products and want to query for the price of a product, your are implicitly applying a schema, because you are assuming that the product you are looking up has a price. When you think about it, a totally schema-less database doesn't make sense because without some set of rules or common fields among your data, your queries would have no value. In this way, you have to manage this schema on your own, and the database won't warn you on things like typos when you query the database.
Aggregate Oriented
Martin Fowler coins the phrase "aggregate-oriented" for describing how data is stored in NoSql database. In Relational databases the translation of an object that contains of non-scalar types, a list of unknown size of friends for a user entity in a language like java, gets transposed across multiple tables in a RDMS leading to the existence of Object Relational Mapping frameworks.. The friend object, (aggregate) in a NoSQL database is stored as a single entity in a NoSQL database, making it aggregate oriented.
The advantage of storing an aggregation or object as a single unit inside the database is when you try and distribute the data. If the object is stored as a single entity, then that entity in complete can be stored on a single machine. When you go to retrieve that entity, you only have to go to one node to access it. In a RDMS system, accessing that same entity would require accessing X number of nodes to access and build all of the data from the different tables.
Restriction on aggregate oriented structure is that is works well as long as the representation you are pushing back and forth remains the same. An order that contains n line orders. However, if you want to pull a different view on the same data, for example a product which has a relationship to n line order, you would have to do some extra work to produce that representation. RDMS has these different data models separate, and with an edit of the query, you can grab and build the aggregate easily that you want to see.
Consistency and Atomicy
In NoSQL database consistency and transactions are true within a single aggregate type, which is typically the use-case for when you need transactions.
Sharding vs Replication
Sharding is when data is broken into chunks and spread across multiple machines as can be done in a RDMS database. Replication is when the same set of data is replicated across multiple machines. Replication introduces some consistency problems, other than the logical problems seen on one machine or with sharding, but at a pro of being more performant and resilient. A number of requests on the same set of data can now be handled by multiple nodes, and if one of the nodes goes down, there is another node with the same set of data that can take its place. Sharding is complicated to implement, but it also introduces performance since each data set on the servers are smaller and faster to search with smaller indexes.
Cap Theorem (Consistency, Availability, Partition):
You can guarantee any two of these. In a NoSQL database that is distributed, we assume that we are using a partitioned database. In this case then, you can only guarantee consistency or availability. Which one you guarantee is a business choice that you can make. This is determined by the implementation of the action that you take when a communication line goes down between partitions. Either you determine the system to be "down" and don't accept any requests to the database (consistency over availability) or you leave the system "up" and hope there are no conflicts while the communication line is down (availability over consistency). In RDMS on a single server, you don't have partitions so you can guarantee both consistency and availability.
Even though in theory the Cap Theorem makes sense, in practice, a more common tradeoff is revealed which is consistency vs response time. A consistent request needs to wait for all the nodes involved to be updated before receiving a response. If a large number of nodes are involved, this response time may not be acceptable to the user, which leads to "eventually consistent" database writes.
Reasons for NoSQL:
If you are not Google or Amazon, then you have no need for a distributed NoSQL database. Even though you may not have the data now, choosing an implementation that is able to scale is often a good idea for the future.
But if you don't care about scaling, another reason for choosing NoSQL is because its easier to use in development. Aggregate types are natural in programming languages that support non-scalar types, and its easier to store those types as a single entity in a NoSQL database, rather than having to deal with Object-Relational Mapping into an RDMS system.
Friday, August 1, 2014
Thursday, July 31, 2014
NoSQL vs SQL
https://www.youtube.com/watch?v=rRoy6I4gKWU
NoSQL databases came about because of the need to store very large amounts of data and the need to store this data and traffic access to that data on multiple servers. RDMS was designed to work well on a single machine, but there is only so far a single machine can be scaled vertically and you quickly hit the limits when dealing with the amount of data handled by companies like Amazon or Google. NoSQL releases some of the ACID (Atomicity, Consistency, Isolation, Durability) restrictions of RDMS database allow it to distribute across multiple data centers, but of course, there are some drawbacks to this. Let's go through a few topics and see for each type of data storage, the pros and cons for those topics
Queries:
In relational databases, there is no limit on the queries you can write. Complexity of queries include multiple joins across different relational tables in the same database, whereas this data is located and scaled vertically in the same location. NoSQL databases on the other hand because of their distributed nature need to be denormalized ahead of time, by either combining data modules into one view, or by writing map reduce functions whose outputs are maintained and updated as new writes enter the database. If you know what queries you want to do ahead of time, then you might find NoSQL to be fast, because mapreduce functions can compute in parallel.
Transactions:
Traditional relational databases prided themselves in supporting transactions where you can edit anything in the world within a single transactions. NoSQL distributed nature is again a factor here, as it can't gaurenttee atomic operations since it doesn't know where the data is stored. Google App Engine datastore gets around this issue by introducing entity groups, and supporting transactions within an entity group. It actually support cross entity transactions as well, but those transactions are limited to 5. So, if you can structure your data in entity groups, or deal with the limits of 5 entities per cross-transaction, then NoSQL and Google App Engine datastore would work fine, otherwise you want the ACID qualities of RDMS.
Consistency:
NoSql only gaurentees "eventually consistent" data
Scalability:
Obviously the reason for NoSQL in the first place, data can be stored on multiple data centers with no master, with the support of mapreduce functions to get the data that you need. RDMS databases have gotten better at vertical scaling however.
Management:
Because of the less restrictions, developers can find that their time to their first MVP is faster, because of the less overhead of setting up SQL database.
Schema:
Part of the setup for a SQL RDMS database is a schema, and managing changes in the schema can be complex. With NoSQL they don't have those limitations, making changes to schemas having a lesser effect.
NoSQL databases came about because of the need to store very large amounts of data and the need to store this data and traffic access to that data on multiple servers. RDMS was designed to work well on a single machine, but there is only so far a single machine can be scaled vertically and you quickly hit the limits when dealing with the amount of data handled by companies like Amazon or Google. NoSQL releases some of the ACID (Atomicity, Consistency, Isolation, Durability) restrictions of RDMS database allow it to distribute across multiple data centers, but of course, there are some drawbacks to this. Let's go through a few topics and see for each type of data storage, the pros and cons for those topics
Queries:
In relational databases, there is no limit on the queries you can write. Complexity of queries include multiple joins across different relational tables in the same database, whereas this data is located and scaled vertically in the same location. NoSQL databases on the other hand because of their distributed nature need to be denormalized ahead of time, by either combining data modules into one view, or by writing map reduce functions whose outputs are maintained and updated as new writes enter the database. If you know what queries you want to do ahead of time, then you might find NoSQL to be fast, because mapreduce functions can compute in parallel.
Transactions:
Traditional relational databases prided themselves in supporting transactions where you can edit anything in the world within a single transactions. NoSQL distributed nature is again a factor here, as it can't gaurenttee atomic operations since it doesn't know where the data is stored. Google App Engine datastore gets around this issue by introducing entity groups, and supporting transactions within an entity group. It actually support cross entity transactions as well, but those transactions are limited to 5. So, if you can structure your data in entity groups, or deal with the limits of 5 entities per cross-transaction, then NoSQL and Google App Engine datastore would work fine, otherwise you want the ACID qualities of RDMS.
Consistency:
NoSql only gaurentees "eventually consistent" data
Scalability:
Obviously the reason for NoSQL in the first place, data can be stored on multiple data centers with no master, with the support of mapreduce functions to get the data that you need. RDMS databases have gotten better at vertical scaling however.
Management:
Because of the less restrictions, developers can find that their time to their first MVP is faster, because of the less overhead of setting up SQL database.
Schema:
Part of the setup for a SQL RDMS database is a schema, and managing changes in the schema can be complex. With NoSQL they don't have those limitations, making changes to schemas having a lesser effect.
Tuesday, November 5, 2013
Guice... What is it good fer?
Guice is a dependency injection framework written by Google, and it is used in many of Google's other software products. Guice can be closely compare to Spring; both are dependency injection frameworks, but Guice adds the benefit of type safety.
So why do you want to use Guice? Well let's start with what how you are currently writing code.
The Problem:
Currently you might be writing code that looks like this:
Dependency Injection:
To solve the problem, we will "inject" the dependency into the constructor.
Our tests no longer relies on our DbWriter class. If DbWriter changes, this test will not fail. There are few libraries out there to easily create mocks. EasyMock is my favorite.
Guice:
So if you are thinking ahead you might realize that strictly implementing dependency injection introduces a cascading problem. If we are passing in every dependency into every class, where do we instantiate all the objects? Short answer: main().2
Believe it or not, I think this situation is ideal. You have a separation of concerns with the object creation and program execution1. All of the classes can be tested independently, and are more easily reused.
Instead of specifying every dependency in main, we can specify the dependencies using Guice modules:
Extra boilerplate is required for Guice. Activate your module from main like so:
And you have to specify that you want your classes to be injected by using the @Inject annotation on your constructor.
I only gave one use-case for Guice. There are many other built in features including method and field injection, defining scopes (singletons), etc- which you can read about on their website.
For android developers out there I recommend a different dependency injection framework by Square called Dagger. It has less features than Guice, but it uses a annotation processor to build the object graph at compile time, instead of using reflection at run-time. This decreases the run-time overhead on the already stressed hardware of smartphones.
1 Robert Martin's Clean Code
2 You can also use factories, but that's a lot of boilerplate to do that for every dependency.
So why do you want to use Guice? Well let's start with what how you are currently writing code.
The Problem:
Currently you might be writing code that looks like this:
public class DataProcessor{
public DataProcessor(){}
public void processData(D data)
{
//Do something with data
// Save data
DbWriter myDbWriter = new DbWriter();
myDbWriter.write(data);
}
}
Dependency Injection:
To solve the problem, we will "inject" the dependency into the constructor.
public class DataProcessor{
private DbWriter myDbWriter;
public DataProcessor(DBWriter dbWriter){
myDbWriter = dbWriter;
}
public void processData(D data)
{
//Do something with data
// Save data
myDbWriter.write(data);
}
}
public class DataProcessorTest{
private DataProcessor classUnderTest;
@Test
public void testProcessData()
{
mockDbWriter = new DbWriterStub();
classUnderTest = new DataProcessor(mockDbWriter);
classUnderTest.processData();
// Check mock to make sure we saved the data
}
}
Our tests no longer relies on our DbWriter class. If DbWriter changes, this test will not fail. There are few libraries out there to easily create mocks. EasyMock is my favorite.
Guice:
So if you are thinking ahead you might realize that strictly implementing dependency injection introduces a cascading problem. If we are passing in every dependency into every class, where do we instantiate all the objects? Short answer: main().2
public static void main(String [] args){
Application myApplication = new Application(new A(new B(...)));
myApplication.start();
}
Believe it or not, I think this situation is ideal. You have a separation of concerns with the object creation and program execution1. All of the classes can be tested independently, and are more easily reused.
Instead of specifying every dependency in main, we can specify the dependencies using Guice modules:
import com.google.inject.AbstractModule;
public class MyGuiceModule extends AbstractModule{
protected void configure() {
bind(Applicaiton.class).to(MyApplication.class);
bind(A.class).to(AImpl.class);
bind(B.class).to(BImpl.class);
}
}
Extra boilerplate is required for Guice. Activate your module from main like so:
public static void main(String [] args){
Injector injector = Guice.createInjector(new MyGuiceModule());
Application myApplication = injector.getInstance(myApplication.class);
myApplication.start();
}And you have to specify that you want your classes to be injected by using the @Inject annotation on your constructor.
@Inject
public DataProcessor(DBWriter dbWriter){
myDbWriter = dbWriter;
}
I only gave one use-case for Guice. There are many other built in features including method and field injection, defining scopes (singletons), etc- which you can read about on their website.
For android developers out there I recommend a different dependency injection framework by Square called Dagger. It has less features than Guice, but it uses a annotation processor to build the object graph at compile time, instead of using reflection at run-time. This decreases the run-time overhead on the already stressed hardware of smartphones.
1 Robert Martin's Clean Code
2 You can also use factories, but that's a lot of boilerplate to do that for every dependency.
Thursday, September 26, 2013
Java: Pass by Value
Alright alright alright. So, here is the earth. (Round)
For those of you mingling in multiple languages it is hard to keep it all straight. Are parameters passed into functions pass-by-value? or pass-by-reference?
Let's get straight to the point. We are talking about Java here, and Java is pass by value. But I think that people are confused about what pass by value in java really means.
Let's look at an example.
What is the result of the system.out.print line above? If its pass by value the value should be 5, right? WRONG.
Even though Java is pass by value, this common misconception gets a lot of people. Java passes object references by value, not the objects themselves. What do I mean by that? Well let's look at how a reference works conceptually.
This is what we get when we do "MyObject oMain = new MyObject();"



For those of you mingling in multiple languages it is hard to keep it all straight. Are parameters passed into functions pass-by-value? or pass-by-reference?
Let's get straight to the point. We are talking about Java here, and Java is pass by value. But I think that people are confused about what pass by value in java really means.
Let's look at an example.
public void passByValue(MyObject oParam){
oParam.myAttribute = 10;
}
public static void main(String [] args)
{
MyObject oMain = new MyObject();
oMain.myAttribute = 5;
passByValue(oMain);
system.out.print(oMain.myAttribute)
}
What is the result of the system.out.print line above? If its pass by value the value should be 5, right? WRONG.
Even though Java is pass by value, this common misconception gets a lot of people. Java passes object references by value, not the objects themselves. What do I mean by that? Well let's look at how a reference works conceptually.
This is what we get when we do "MyObject oMain = new MyObject();"
Now, when we pass in "oMain" as a parameter to the function "passByValue", the value of the reference is copied to the new parameter "oParam":

Now you can see that any modifications to the "oParam" reference, is acting on the same object that the "oMain" reference is pointing to.
Things get interesting when we introduce the "new" operator into the discussion. The "new" operator allocates a new instance of an object, and sets the reference to point to that object. So say we rewrite our code above to:
public void passByValue(MyObject oParam){ oParam = new MyObject();
oParam.myAttribute = 10;
}

This leads into the discussion of "defensive copying". When we use the "new" operator we ensure that our method does not change the value of the object passed in. Of course, if you are passing in immutable objects, there is no need for this.
Defensive copying is often used when passing Lists.
public void passByValue(List<MyObject> list){ list = new List<MyObject>(list); // clone list
// do something with new list
}Thursday, September 19, 2013
POST vs PUT
Theodore came up to me the other day and said: "Hey John, I want to add this data to the database on the server, do I want to use HTTP POST? Or HTTP PUT?
Good question, Theo. Actually, either POST or PUT can be used to create or update data on the server, but they are different.
The details are elaberated on in the HTTP spec:
"The fundamental difference between the POST and PUT methods is
target resource in a POST request is intended to handle the enclosed
representation as a data-accepting process, such as for a gateway to
some other protocol or a document that accepts annotations. In
contrast, the target resource in a PUT request is intended to take
the enclosed representation as a new or replacement value."
So, to reiterate: POST means you are sending data to a resource that already exists. The resource (which you can look at as a java servlet or a script) processes the data and decides the implications to the online database. PUT means you want the data included with the request to be furthermore represented by the URL of the request. If there is data at the URL already, update it. If there is no data, create it.
"A successful PUT of a given representation would suggest that a subsequent GET on that same target resource will result in an equivalent representation being returned..."Make sense?
A interesting inherited characteristic of PUT is that it is idiomatic. Which means that multiple requests to the same URL with the same data has no effect. This may come in handy when you lose your connection mid-request.
A hypothical example or using POST and PUT:
Let's say you want to add some data onto a message board website. You find an interesting forum topic, "Glaciers... why do they move so slow?" and want to post a comment. This will probably be done with http POST.
www.glacierforums.com/addCommentToforum?id=235434Send a request to this URL with a message, and the resource located at "www.glacierforums.com/addCommentToforum" will take the input of "?id=235434" along with your message sent in the request and deal with making sure that this message is added on to the end of forum page.
Now for the same example, you decide that your profile alias "DarthGlacier" is dumb. Nobody references Star Wars nowadays anyway. So you update your user info by sending your new user information (via JSON or whatnot) with a http PUT to this URL.
www.glacierforums.com/users/352343Your user information, which is located at the URL: www.glacierforums.com/users/352343, has now been updated. A HTTP GET with this URL will return the same user information that you sent to it.
This example assumes you have assumed all authentication privileges needed to write data on to the server.
Wednesday, August 21, 2013
Why Git is Awesome
Having used SVN and Clearcase extensively before coming around to using Git, I feel that I have a good background to support my decision to choose Git over lessor VCS's. For the sake of comparison, I will directly compare Git to SVN, but in general, points made in this post can be made for any non-distributed vs distributed VCS's.
Git is awesome because:
Git is awesome because:
- It is distributed.
When you work in git, the first thing you typically do is copy someone else's existing git repository with "git clone." This is opposed to interacting with the location of the central repository over the lifetime of your development. This is one big bullet point that infers many concrete benefits:
- Better collaboration: Whenever you do something in SVN, everybody knows about it. In Git, when you clone a repository, you are the project owner of your own local copy and its private until you want to make it public. It doesn't matter how many times people clone the central repository, you will never know the difference. This design has led to the great success of open-source projects. Communities of developers feel at ease in forking a repository and doing their own work without ever risking breaking the trunk code base.
- No noise in central: An extension to the previous point, in which project owners in SVN know who their collaborators are. To create a branch in SVN, you create a new directory in which you copy all the code to, and this directory lives on the central repository. In Git, you create branches on your own repository, a repository in which you own and is private. No more problems with developers leaving the company or forgetting to clean up their branches, leaving behind a mess in the SVN repository.
- Access control: Both repository systems allow you to control read and write permissions. But, developers who don't have write access in SVN, can't use version control at all. Developers using Git can keep their changes under version control in their own local repository for a later date when they have permission to publish.
- Work offline: Because you have your own copy of the repo, you can work offline and as a result can work well and fast with slow/no network access.
- Backups: Every time you clone the repo, you are creating a backup, in case the central repo fails for some reason.
- Flexible work flow: Git is extremely flexible. In Git, there is no "central" repository. Every Git repository is the same, and every repository can interact with each other in the same ways. Because of this loose coupling, there is a lot of flexibility in the collaboration of teams. An example here:
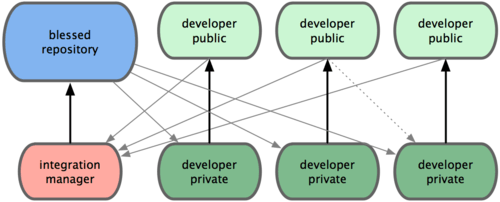
In this example the developers request the integration manager to pull each of their requests. The manager handles the merging, before pushing into the "central" repository. The integration manager interacts with the developer's repos the same way it interacts with the "central" repository.The point of all these being that you can manage any workflow independent of a central repository.
2. Branching is Easier
I haven't really seen this problem when I used SVN, but I have been told by others- that people don't like making branches in SVN to the point that they just don't do it. This is bad. Committing to trunk is bad. After writing this I talked with a colleague who told me about continuous integration. Though I have heard this term before, I didn't associate that as a opposing force to "committing to the trunk is bad." So I'm retracting this statement, and I will do a future post about continuous integration. There is still the point that developers should be able to create branches easily for experimentation or whatnot. With Git, creating, switching to and deleting branches is easy, so developers won't think twice about creating an experimental branch, or one to start developing a new feature on.
- People don't branch in SVN: There are few reasons why people don't like branching in SVN. One is you usually have to type in a long URL where the SVN repo is located... twice. Once for copying from and once for copying to. This operation takes a few seconds, as you are copying the entire branch over. When its all over, you have a directory on the SVN server that everybody can see with your name spelled wrong.
- Branching in Git at two levels:
- The first level of branching in Git people don't really realize, that is "git clone". Whenever you clone a repo, you are copying the code base from one place to another, effectively creating a branch off the original code base. In fact, the command is similar in speed of execution and annoying-ness as creating a branch in SVN. The difference is that you are required to clone, there is no other option. This forces the workflow of separating a developer's workspace from the trunk.
- The second level of branching is with the "git branch" command. To create a branch in git you do. "git branch <branch_name>". This is very fast and lightweight command. More so, switching branches is just as easy, just do: "git checkout <branch_name>". This additional second level of branching not present in SVN give developers flexibility to separate their features, bugs and experiments at their discretion. The added complexity is managed by them, not the central server, and pushing changes to the server is selective to only the branches of their choosing.
3. Faster and Smaller
I won't go too much into detail about this, and you can look into the specific implementations of Git and SVN to understand why Git is faster and smaller. But, its a good thing.
Thursday, August 15, 2013
An Introduction to LDAP
The Lightweight Directory Access Protocol is a protocol that sits in the application layer1. The protocol is used for accessing and maintaining internals of distributed directory services- which are covered by the x.500 standard series3.
LDAP derived from DAP, that used to run only on a deployed OSI2 network. As the TCP/IP network stack took over the internet, LDAP rose up as the TCP/IP alternate to DAP. The L ("lightweight") comes from the significant less bandwidth required for transactions.
To start a LDAP session, a client connects to a LDAP server (a Directory System Agent (DSA) in x.500 terms). Client will make requests to server, and server will respond to requests - all asynchronously. All information is sent using Basic Encoding Rules (BER)4. After initial connection the user must send a request to BIND, that will authenticate the user.
Directory Structure:
An example of an entry stored in LDAP:
"dn" is the distinguish name that is a composite of cn "common name" and one or more dc's "domain component." cn translates to a file name in a file system, and the collection of dn's would be the file path. It works most specific first then up. So above would translate in linux to com/example/John Doe.
Every line above is an attribute, which has the following syntax:
<key>:<value>
A class in LDAP defines a set of attributes that an entry can define. Classes can inherit from other classes and so a subclass will inherit all of its parents attributes by definition. (Normal OO stuff). The objectClass attribute defines classes that this entry uses (that then define what attributes it can set). "top" is the abstract parent class of all other classes. (either directly or indirectly)
Operations:
The data for Operation requests sent by the client are in similar format to how entries are represented on the LDAP servers. For example, the following data is for an ADD operation:
3Series of computer networking standards for directory services created by ITU-T(ITU Telecommunications Standardization Sector)
4AKA x.690 ->Format for encoding ASN.1 data structures.
LDAP derived from DAP, that used to run only on a deployed OSI2 network. As the TCP/IP network stack took over the internet, LDAP rose up as the TCP/IP alternate to DAP. The L ("lightweight") comes from the significant less bandwidth required for transactions.
To start a LDAP session, a client connects to a LDAP server (a Directory System Agent (DSA) in x.500 terms). Client will make requests to server, and server will respond to requests - all asynchronously. All information is sent using Basic Encoding Rules (BER)4. After initial connection the user must send a request to BIND, that will authenticate the user.
Directory Structure:
An example of an entry stored in LDAP:
dn: cn=John Doe,dc=example,dc=com cn: John Doe givenName: John sn: Doe telephoneNumber: +1 888 555 6789 telephoneNumber: +1 888 555 1232 mail: john@example.com manager: cn=Barbara Doe,dc=example,dc=com objectClass: inetOrgPerson objectClass: organizationalPerson objectClass: person objectClass: top
Every line above is an attribute, which has the following syntax:
<key>:<value>
A class in LDAP defines a set of attributes that an entry can define. Classes can inherit from other classes and so a subclass will inherit all of its parents attributes by definition. (Normal OO stuff). The objectClass attribute defines classes that this entry uses (that then define what attributes it can set). "top" is the abstract parent class of all other classes. (either directly or indirectly)
Operations:
The data for Operation requests sent by the client are in similar format to how entries are represented on the LDAP servers. For example, the following data is for an ADD operation:
dn: uid=user,ou=people,dc=example,dc=com changetype: add objectClass: top objectClass: person uid: user sn: last-name cn: common-name userPassword: password
In the above example,uid=user,ou=people,dc=example,dc=commust not exist, andou=people,dc=example,dc=commust exist.
The complete list for operations is as follows:
- StartTLS — use the LDAPv3 Transport Layer Security (TLS) extension for a secure connection
- Bind — authenticate and specify LDAP protocol version
- Search — search for and/or retrieve directory entries
- Compare — test if a named entry contains a given attribute value
- Add a new entry
- Delete an entry
- Modify an entry
- Modify Distinguished Name (DN) — move or rename an entry
- Abandon — abort a previous request
- Extended Operation — generic operation used to define other operations
- Unbind — close the connection (not the inverse of Bind)
3Series of computer networking standards for directory services created by ITU-T(ITU Telecommunications Standardization Sector)
4AKA x.690 ->Format for encoding ASN.1 data structures.
Subscribe to:
Posts (Atom)